
Начнем с самого простого, если перевести понятие Big Data на человеческий язык, когда мы говорим о больших данных, мы имеем в виду даже не сами данные, а различные инструменты, подходы и методы обработки данных для того, чтобы после использовать их под конкретные задачи и цели. Огромные объёмы данных обрабатываются для того, чтобы человек мог получить конкретные и нужные ему результаты, для их дальнейшего эффективного применения. На сегодняшний день нет четкого понятия, какое именно количество является большими данными — 500ТР или 100Gb в день.
Большие данные — это информация, которая не поддается обработке классическими методами, по объему превосходящая жесткий диск одного персонального устройства, данные, которые нельзя обработать на одном компьютере, в excel, плюс эти данные растут с каждым днем. Данные делятся на структурированные (excel таблица) и неструктурированные (данные, которые не приведены в рабочий вид: видео, картинки, аудиофайлы).
Основными агрегаторами данных являются пользователи, а также поисковые роботы, камеры видеонаблюдения, gps-навигаторы, банковские операции, ежесекундно гигантские объемы контента генерируют социальные сети, СМИ, видеохостинги (youtube), мессенджеры, и это лишь сотая часть поставщиков данных.
Где применяются большие данные?
В развитых странах бизнес все чаще обращается к серьезным решениям для анализа данных, для измерения и повышения их производительности. Будь то банковское дело, розничная торговля, страхование, телекоммуникации, добыча полезных ископаемых, производство, обслуживание клиентов или конкурентные виды спорта, большие данные становятся решающим фактором в формировании стратегии будущего в бизнесе.
Вот еще ошеломляющая статистическая информация о количестве больших данных, которые генерируются в разных отраслях:
• Facebook собирает и обрабатывает более 10 терабайт данных согласно отчету IBM.
• Чипы на топливно-масляных установках генерируют 5 терабайт данных каждую минуту.
• Счетчик реактивного двигателя генерирует 10 терабайт данных каждые 30 минут.
В глобальном масштабе ежедневно генерируется более 2,5 квинтиллионов байтов данных — это 2,5, за которыми следуют 17 нулей!
Все эти примеры подтверждают одно и то же повествование: данные являются еще одним ресурсом для экономического вклада, подобно труду, капиталу и технологиям.
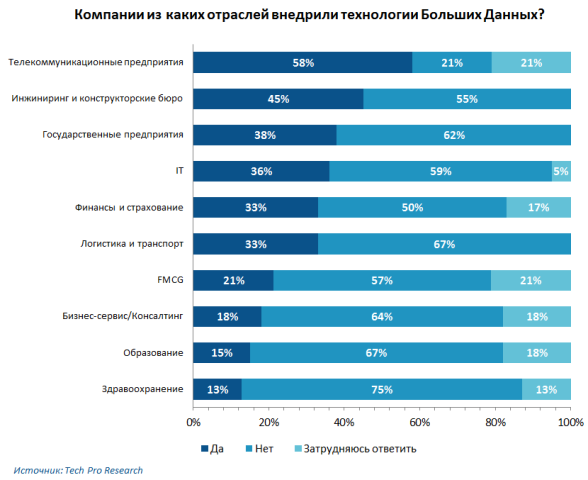
Опрос проводил Tech Pro Research:
Какие перспективы на рынке Казахстана?
По прогнозу IBM, к 2020 году для специалистов этого профиля откроются более 700 тыс. вакансий. На Западе трансформация уже началась, если сейчас термин Big data на территории СНГ является более популярным среди IT-специалистов, лидеры рынка начали адаптацию обучающими программами, тренингами для классических аналитиков. Кроме того, функционал традиционных должностей будет расширяться, сотрудники будут учиться грамотно работать с большими данными и, следовательно, пользоваться новыми преимуществами, которые дает эта технология. В итоге мы придём к тому, что абсолютно все сотрудники, не только представители IT-отделов, овладеют методами работы с Big Data.
К примеру, в следующем году 62% компаний планируют внедрять machine learning (машинное обучение) и основные методы анализа Big Data, следовательно, организациям нужно будет искать наиболее эффективные способы адаптации сотрудников к этим изменениям.
Технологии по обработке Big Data только заходят на отечественный рынок, на самом деле сейчас никто не может похвастаться крупными внедрениями и результатами. Со стороны государства ведется большая работа по цифровизации, доказательства тому Цифровой Казахстан, smart city и прочие государственные программы. Барьером для зарубежных компаний является маленькое количество численности населения в стране, то есть качество, количество и сроки окупаемости внедрения сильно возрастают.
В Казахстане крупным заказчиком по обработке данных выступает государство, с периода независимости в стране собралось большое количество данных, их нужно обрабатывать и использовать, чтобы контролировать и конкурировать вне страны.
Одно из крупных внедрений будет происходить в министерстве финансов. Так как это направление стратегически важно для статистики и прогнозирования экономики и ВВП. В нашей стране размер неформальной экономики составляет 26%, в России — 39%, на Украине — 46%, а в Азербайджане и вовсе более 67% экономики находится в тени. Одной из стратегических задач является цивилизация малого и среднего бизнеса, для создания белого рынка. Для более точного анализа и быстрых результатов здесь не обойтись без анализа больших данных.
ВмМинистерстве здравоохранения уже начали базовый уровень цивилизации. ЭПЗ (Электронный паспорт здоровья) позволит создать единую базу данных с историей медицинской карты. Если обратиться в больницу, то данные уже вводят в компьютер. Когда картотека данных будет полностью оцифрована, можно прогнозировать и улучшать работу врачей.
Сейчас база министерства образования и науки интегрирована с базами других госорганов на платформе eGov. Всего в общей сложности в министерстве имеется 73 госуслуги. 25 из них автоматизированы. Идет процесс внедрения НОБД (Национальная образовательная база данных), это подсистема СЭО (Система электронного обучения), предназначенная для автоматизации бизнес-процессов по сбору и обработке первичных статистических данных в сфере образования. В НОБД автоматизирован сбор данных для административных отчетов, заполнявшихся вручную и собиравшихся по цепочке: «организация образования — отдел образования — управление образования — МОН РК». Задачи: сбор ведомственной статистики от первоисточников (организаций образования) в автоматическом режиме; хранение и обработка данных; формирование административной отчетности; обеспечение структурных подразделений МОН РК необходимыми для работы статистическими данными. НОБД обеспечивает полный учет обучающихся; выявляет недостоверную информацию респондентов путем исключения дублирования; упрощает процедуру заполнения Паспортов организаций образования; формирует исторический ряд статистических данных; позволяет формировать нерегламентированные отчеты. Будет полностью внедрена до 2020 года.
Бизнесу также интересны большие данные, огромный интерес проявляют банки, да и в принципе любой крупный или средний бизнес, который хранит данные. Пример тому — «Казпочта» и «Казахтелеком», которые уже начали проявлять интерес.
Рынок по обработке больших данных очень перспективен, если смотреть в будущее. В стране отсутствуют специалисты, спрос на которых с каждым годом увеличивается. Средняя заработная плата на рынке Junior Data Scientist составляет от 200 000 тенге и доходит до 500 000 тенге в месяц.
Автор: Сергей Ахметов, эксперт в области обработки больших данных (Big Data).
Источник: kapital.kz
Фото: kapital.kz
{kind=link}